|
Federico Cocchi
Researcher in Multimodal I am an Applied Scientist at Amazon, working on multimodal systems within the EU International Technology organization. My research focuses on improving how models reason across heterogeneous data sources, combining vision and language. I am currently completing my National PhD at the AImageLab (UNIMORE), under the supervision of Prof. Rita Cucchiara and Prof. Marcella Cornia. During this time, I have worked on several European projects as a Member of Technical Staff. Additionally, I collaborate with CINECA on training large multimodal models on HPC systems. My research journey began during my Bachelor's thesis, where I explored anomaly detection in HPC systems under the supervision of Prof. Michela Milano and Prof. Luca Benini, developing a framework to prevent potential failures in HPC clusters.
Latest News |

|

|

|

|
|
ResearchI am always happy to discuss new ideas and potential research collaborations. Please feel free to get in touch! I am interested in Generative AI - Multimodal Learning - Computer Vision - Natural Language Processing. I have published my research at top-tier conferences, including CVPR, ECCV, ACL, ICCV, and ICPR. |
|
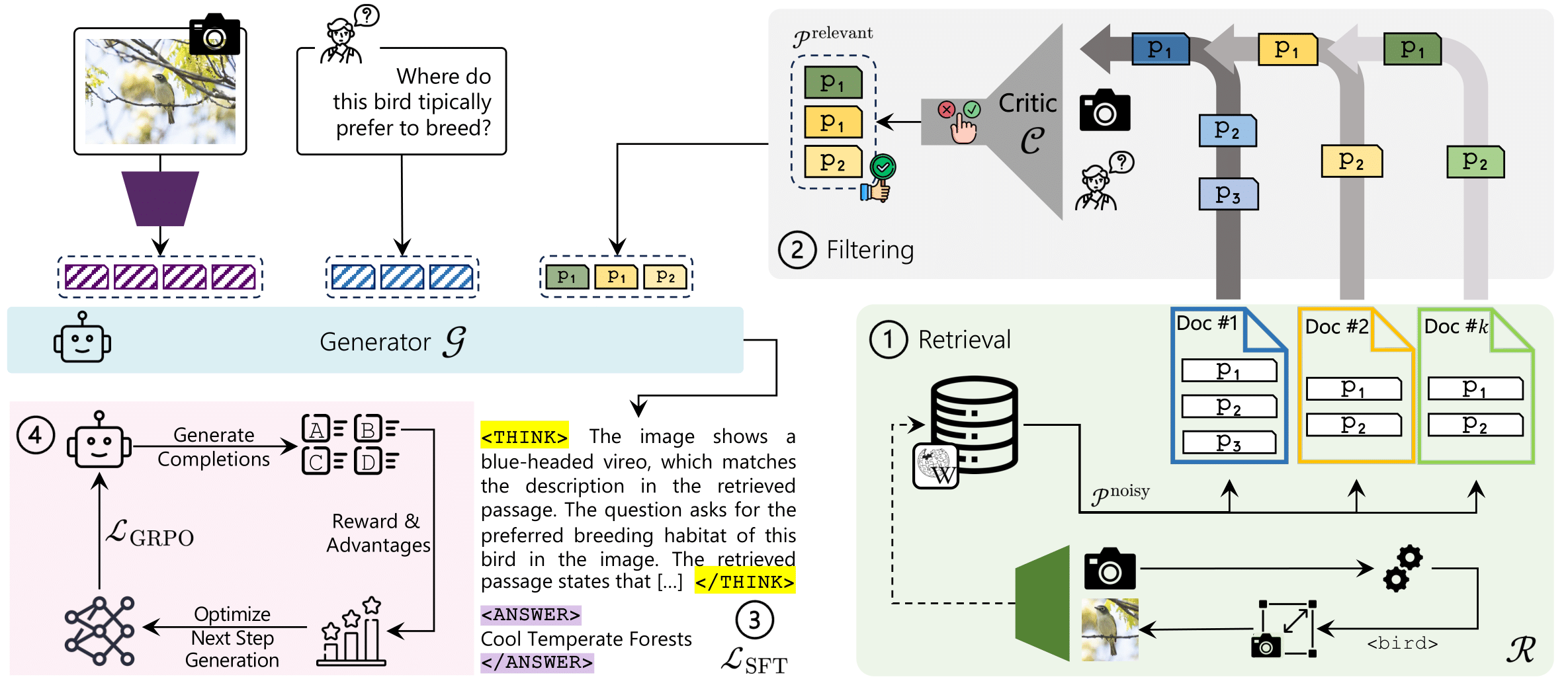
ReAG: Reasoning-Augmented Generation for Knowledge-based Visual Question Answering
Alberto Compagnoni, Marco Morini, Sara Sarto, Federico Cocchi, Davide Caffagni, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara, IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) Highlight, 2026 paper / code ReAG introduce a multi-stage retrieval and reinforcement learning framework that enhances multimodal reasoning over external knowledge, achieving state-of-the-art results on Encyclopedic-VQA and InfoSeek with grounded, interpretable answers. |
|
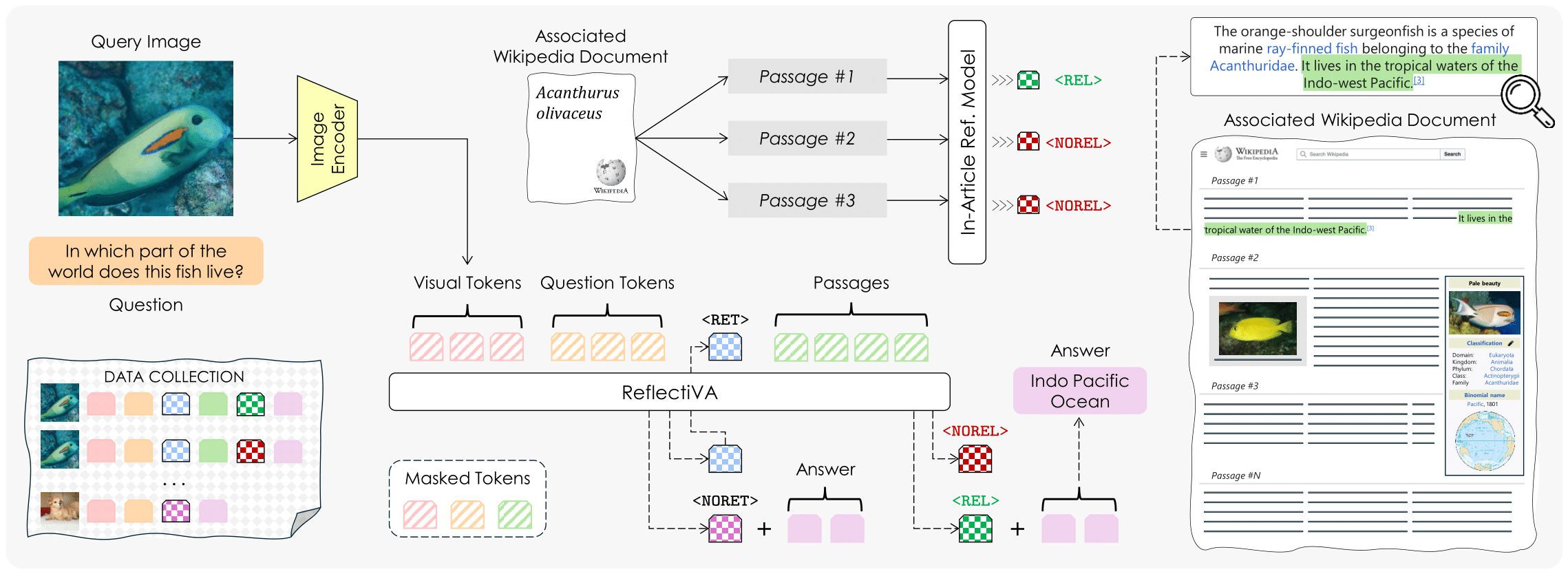
Augmenting Multimodal LLMs with Self-Reflective Tokens for Knowledge-based Visual Question Answering
Federico Cocchi*, Nicholas Moratelli*, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara, IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR), 2025 paper / bibtex Reflective LLaVA (ReflectiVA) enhances Multimodal LLMs by integrating external knowledge, using reflective tokens to determine and retrieve relevant information dynamically. This approach improves knowledge-based visual question answering, outperforming existing methods while maintaining fluency and performance on standard Multimodal benchmarks. |

|
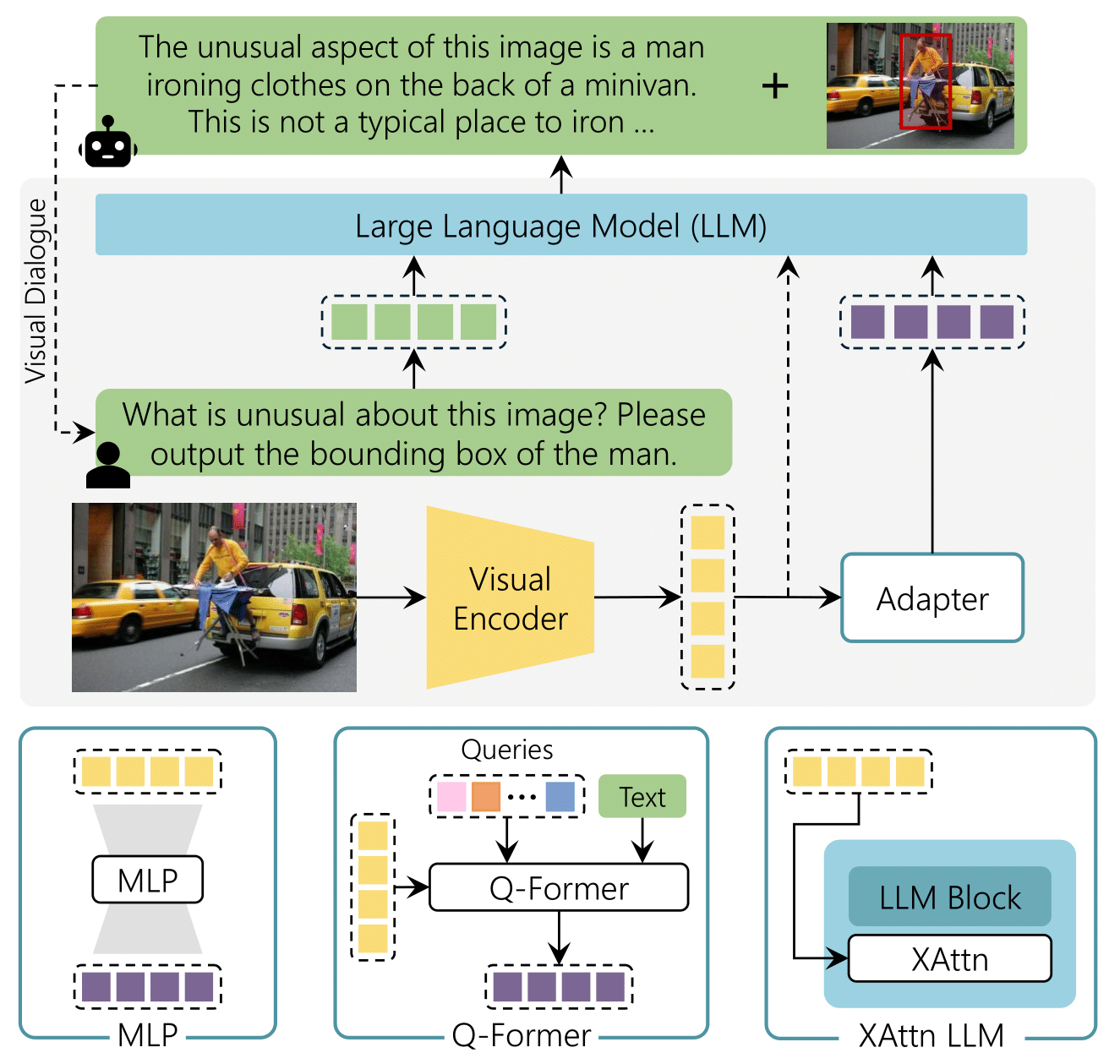
LLaVA-MORE: A Comparative Study of LLMs and Visual Backbones for Enhanced Visual Instruction Tuning
Federico Cocchi*, Davide Caffagni*, Nicholas Moratelli*, Sara Sarto*, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara, International Conference on Computer Vision (ICCV) Workshop, 2025 paper / code / bibtex LLaVA-MORE is a new family of MLLMs that integrates recent language models with diverse visual backbones. To ensure fair comparisons, we employ a unified training protocol applied consistently across all architectures. To further support the research community in enhancing Multimodal LLM performance, we are also releasing the training code and scripts for distributed training. |
|
The (R)Evolution of Multimodal Large Language Models: A Survey
Davide Caffagni*, Federico Cocchi*, Luca Barsellotti*, Nicholas Moratelli*, Sara Sarto*, Lorenzo Baraldi*, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara, Annual Meeting of the Association for Computational Linguistics (ACL) Findings, 2024 paper / poster / bibtex In this paper we introduce the emergence of Multimodal Large Language Models (MLLMs), highlighting their ability to seamlessly integrate both textual and visual modalities. Exploring architectural choices, alignment strategies, and training techniques employed in MLLMs. Additionally, the paper provides insights into the performance and computational requirements of existing models across tasks such as visual grounding, image generation, and domain-specific applications, serving as a foundational resource for future advancements in MLLMs. |
|
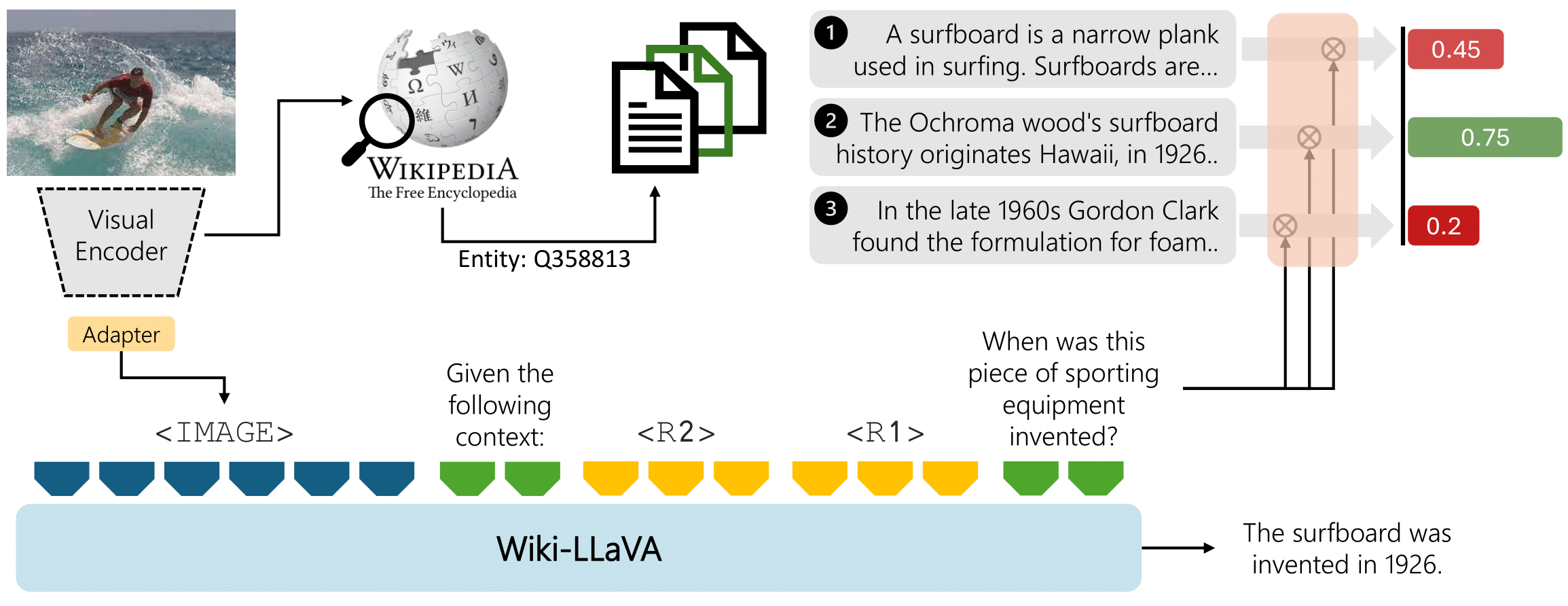
Wiki-LLaVA: Hierarchical Retrieval-Augmented Generation for Multimodal LLMs
Davide Caffagni*, Federico Cocchi*, Nicholas Moratelli*, Sara Sarto*, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara, IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) Workshop, 2024 paper / poster / bibtex Multimodal LLMs (MLLMs) extend the capabilities of LLMs beyond textual modalities. We put our focus on enhancing these models to answer questions that required external knowledge. The proposed approach, Wiki-LLaVA, integrates an external knowledge source via a hierarchical retrieval pipeline. Extracted relevant passages augment the LLM's context, enhancing the precision of generated dialogues. Extensive experiments on question-answering datasets validate the effectiveness of the approach without losing performance in standard multimodal benchmarks (MMMU, POPE, MME, MMB). |
|
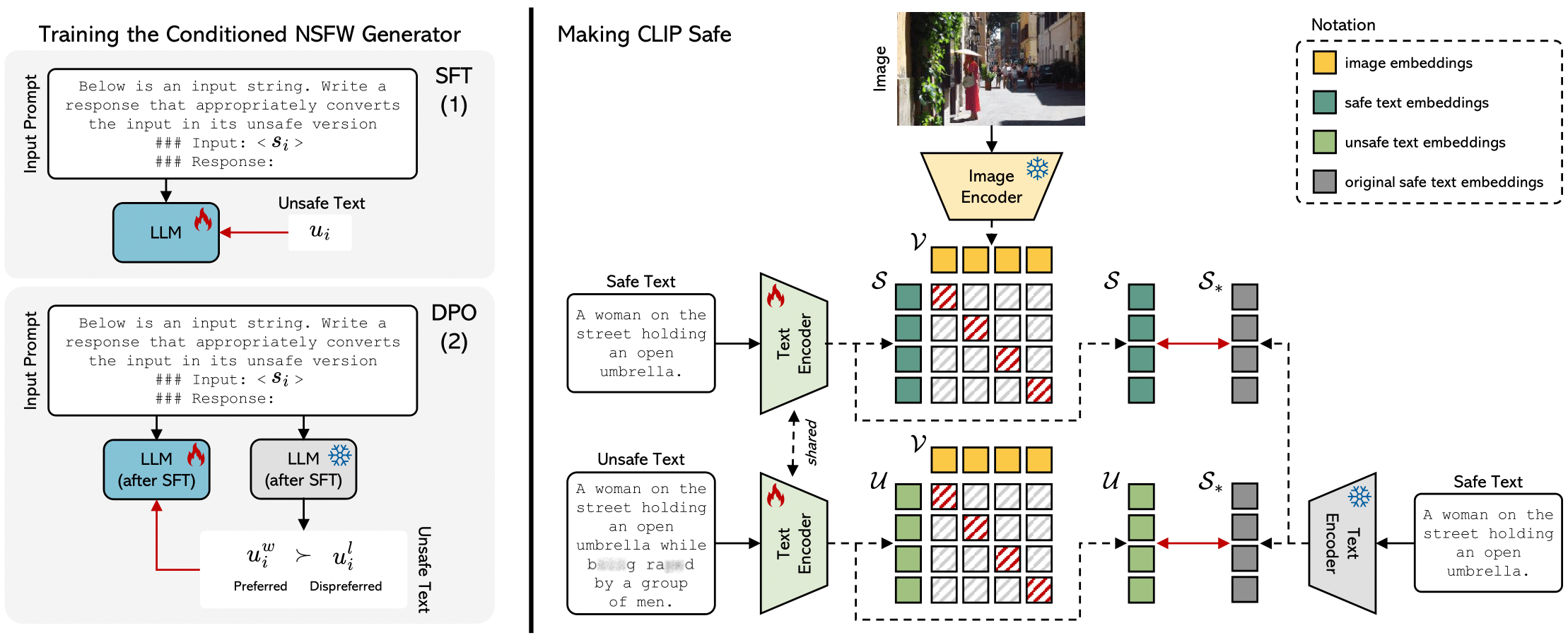
Safe-CLIP: Removing NSFW Concepts from Vision-and-Language Models
Samuele Poppi*, Tobia Poppi*, Federico Cocchi*, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara, European Conference on Computer Vision (ECCV), 2024 paper / code / project page / model / dataset / bibtex This paper improves the safety of Vision-and-Language models like CLIP by reducing sensitivity to NSFW content. Showing results on Image generation and Retrieval. |
|
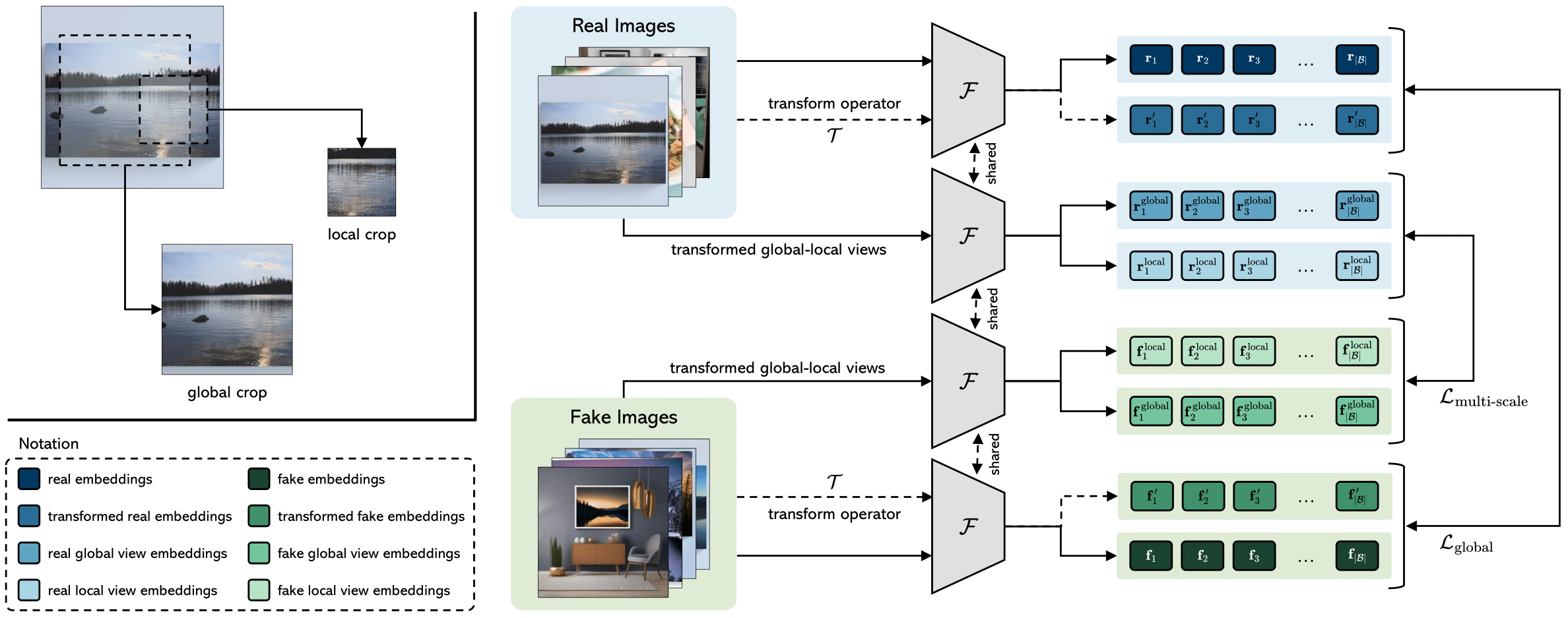
Contrasting Deepfakes Diffusion via Contrastive Learning and Global-Local Similarities
Lorenzo Baraldi*, Federico Cocchi*, Marcella Cornia, Lorenzo Baraldi, Alessandro Nicolosi, Rita Cucchiara, European Conference on Computer Vision (ECCV), 2024 paper / code / project page / dataset / bibtex The study proposes CoDE (Contrastive Deepfake Embeddings), a specialized embedding space for effective deepfake detection. By employing a contrastive-learning approach that emphasizes global-local similarities. |
|
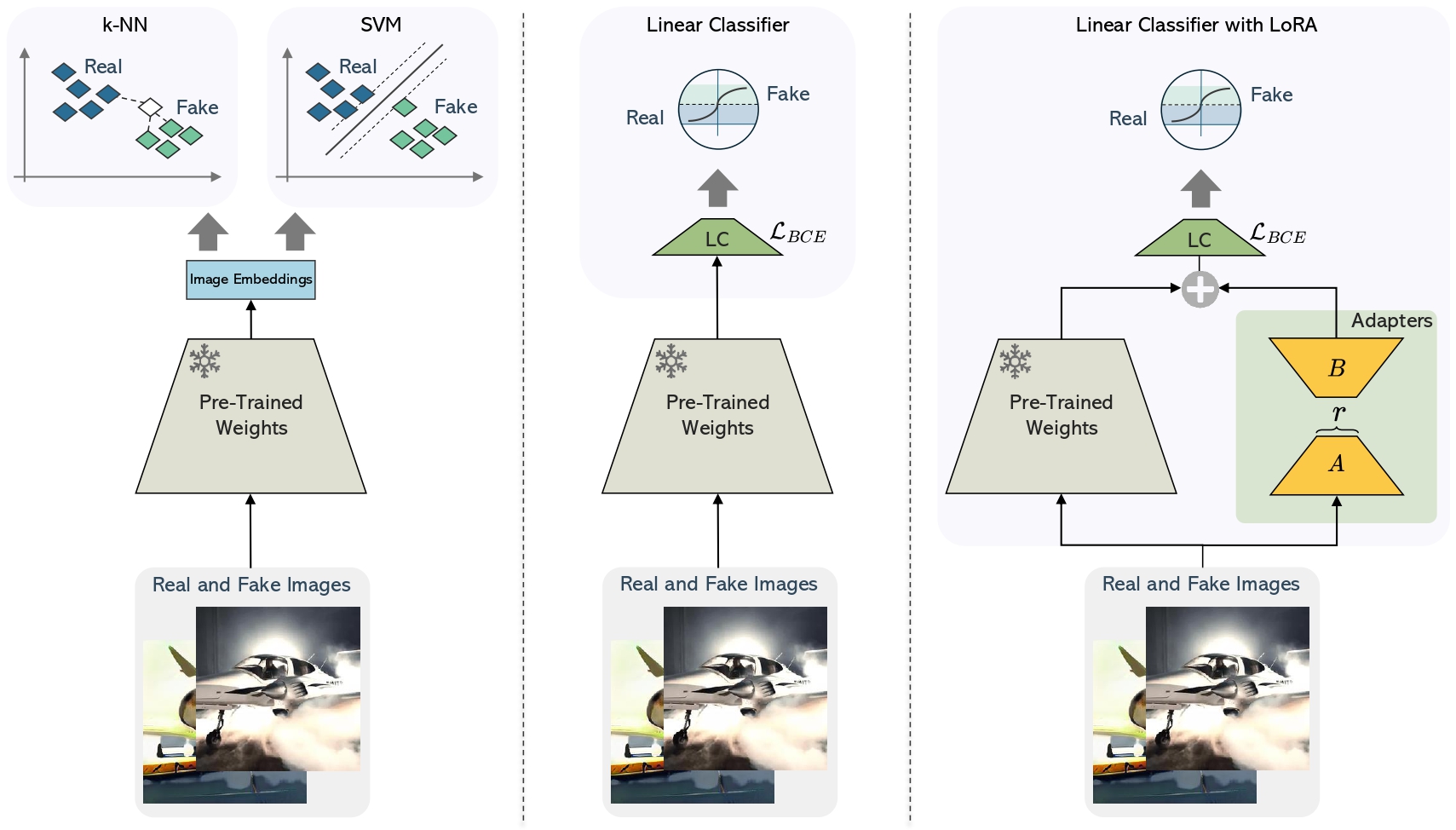
Adapt to Scarcity: Few-Shot Deepfake Detection via Low-Rank Adaptation
Silvia Cappelletti*, Lorenzo Baraldi*, Federico Cocchi*, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara, International Conference on Pattern Recognition (ICPR), 2024 paper / bibtex We propose a novel approach using Low-Rank Adaptation (LoRA) of the CLIP architecture, achieving superior performance in few-shot deepfake detection, even with minimal data, across multiple state-of-the-art generators. |
|
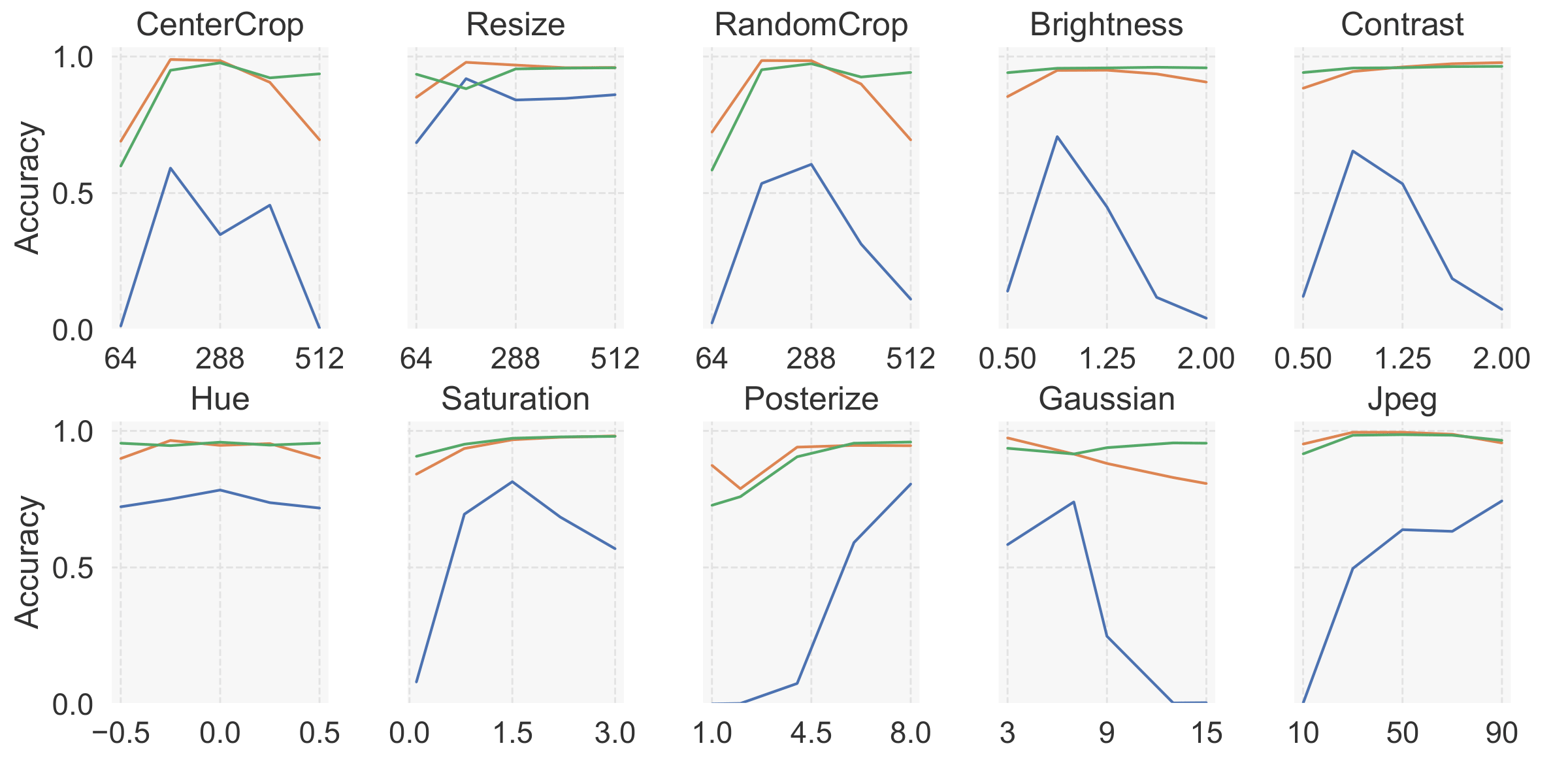
Unveiling the Impact of Image Transformations on Deepfake Detection: An Experimental Analysis
Federico Cocchi*, Lorenzo Baraldi*, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara, International Conference on Image Analysis ans Processing (ICIAP) - ORAL, 2023 paper / bibtex This study delves into the critical realm of deepfake detection, emphasizing the importance of countering the potential misuse of generated media for fake news. More specifically, we investigate the impact of image transformations on the performance of deepfake detectors, considering the most common image manipulations. |
Participation to European and National Projects |
|
|
ELSA - European Lighthouse on Secure and Safe AI
ELSA is a virtual center of excellence that will spearhead efforts in foundational safe and secure artificial intelligence (AI) methodology research. I am involved in the Multimedia use cases. Where I develop new approaches to detect deepfake images to tackle important social challenges such as misinformation. |
|
|
ELLIOT - European Large Open Multi-Modal Foundation Models for Robust Generalization on Arbitrary Data Streams
ELLIOT is the new flagship European Initiative to Research and Develop Open Multi-Modal Foundation Models. The project brings together 30 partners from 12 European countries to develop the next generation of open, trustworthy, and general-purpose multimodal foundation models. The European supercomputing infrastructure—including the EuroHPC systems—will be utilized to train large-scale models on a mix of real and synthetic data sourced from both trusted and public domains. |
|
|
FAIR - Future Artificial Intelligence Research
The FAIR project is a national scale, multidisciplinary initiative aimed at reimagining and developing large-scale foundational models. It explores research questions, methodologies, models, technologies, as well as ethical and legal frameworks for creating Artificial Intelligence systems capable of interacting and collaborating with humans. |
|
|
ITSERR
ITSERR is a interdisciplinary and distributed Research Infrastructure for Religious Studies. I am involved in the project as a PhD student, where I work on creation of Large Language Models for ancient languages, such as Latin. |
Honors & Awards |
|
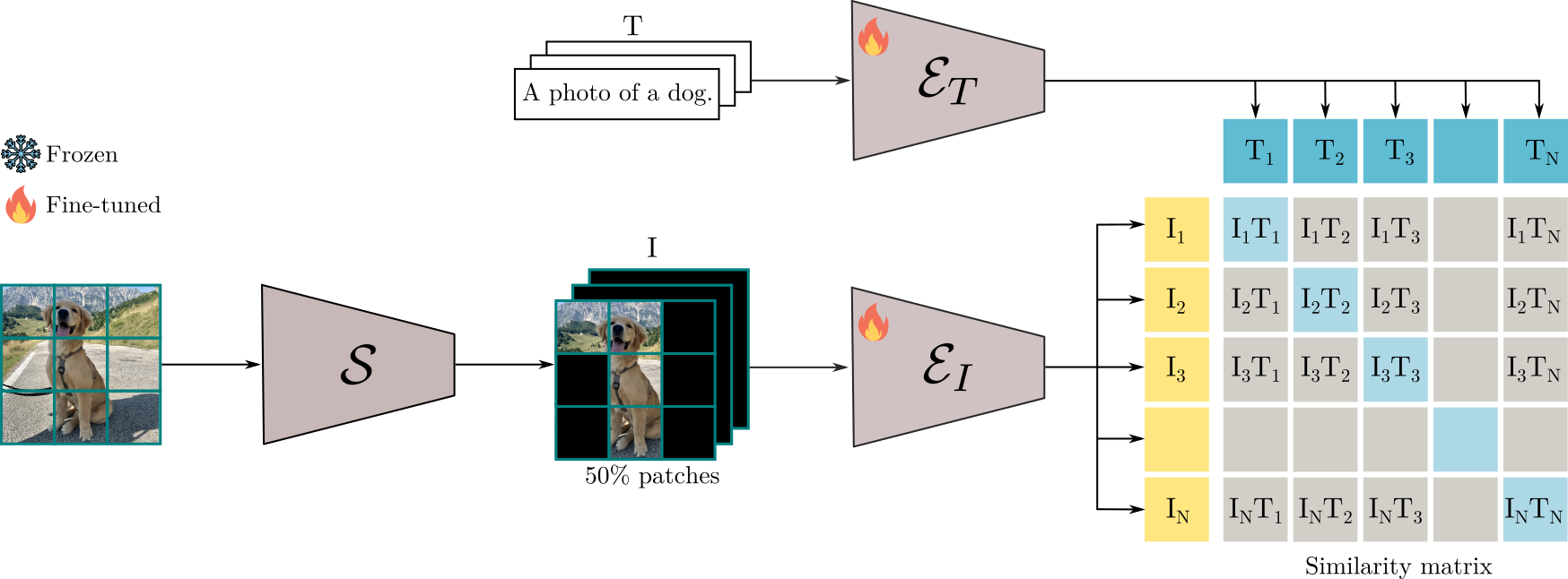
Adaptive Patch Selector for Faster Language-Image Pre-training
Ayush K Rai*, Bo Wan*, Federico Cocchi*, Francesco Tonini*, Giancarlo Paoletti*, Luca Zanella*. ELLIS Summer School, Winner Project, 2023. paper We explore novel methods to enhance masking paradigms such as FLIP, with the objective of accelerating the pre-training process for a Vision-and-Language model. |

|
Contrasting Deepfakes Diffusion via Contrastive Learning and Global-Local Similarities.
Federico Cocchi. Summer School on Signal Processing (S3P), Oral Presentation, 2024. poster Out of over 60 PhD students, my poster was chosen for the plenary oral presentation. |
|
|
Augmenting Multimodal LLMs with Self-Reflective Tokens for Knowledge-based VQA.
Federico Cocchi. ELLIS Winter School on Foundational Models (FoMo), Poster Presentation, 2025. poster |
Mentorship Activities |
|
Selected Activities as Reviewer |
|
|
Website created by Federico | HTML template from Jon Barron |